The sinking of the Titanic is one of the most infamous shipwrecks in history.
On April 15, 1912, during her maiden voyage, the widely considered “unsinkable” Titanic sank after colliding with an iceberg. Unfortunately, there weren’t enough lifeboats for everyone onboard, resulting in the death of 1502 out of 2224 passengers and crew.
- Analyzing each feature and check whether it is important in our analysis?
- What are the most important features to estimate the death?
- Generating new feature to improve the accuracy of model?
Data Understanding:Titanic dataset consists data of 891 people . Dataset was investigated before any preprocessing.
Prepare Data: Including data cleaning, filling NAN value, one-hot encoding and MinMax preprocessing. Please refer to Preprocessing for detail.
Data Modeling: Used GridSearch with 5 folds validation to find best parameter for GradientBoostingRegressor. Some other models are trained and compared as well beforehand. Please refer to Training for detail.
Evaluate the Results: Note book of the analysis is on my git repo, you can directly check that out also.
https://github.com/shadow9909/MyDataScience
Let us now dive into the dataset , here I will not be sharing the code directly. You can see the notebook if you want to refer to the code.
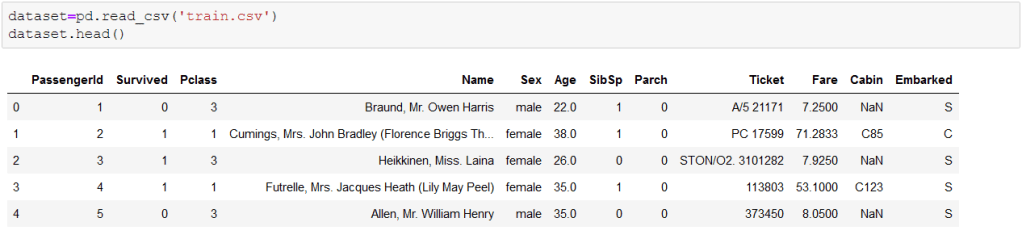
Now let us have a sweet look on the dataset and the values.
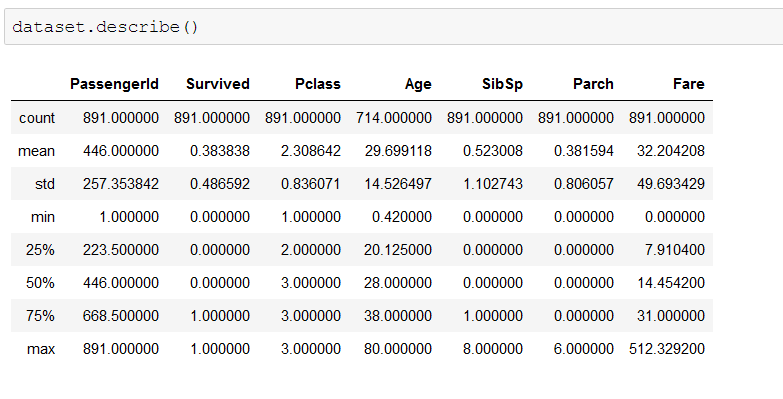
Checking out the distribution of the values in the numerical columns
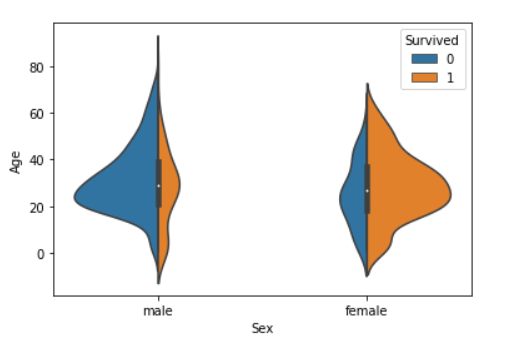
Now let us start our column wise analysis

Well we surely saw some serious gender discrimination here.
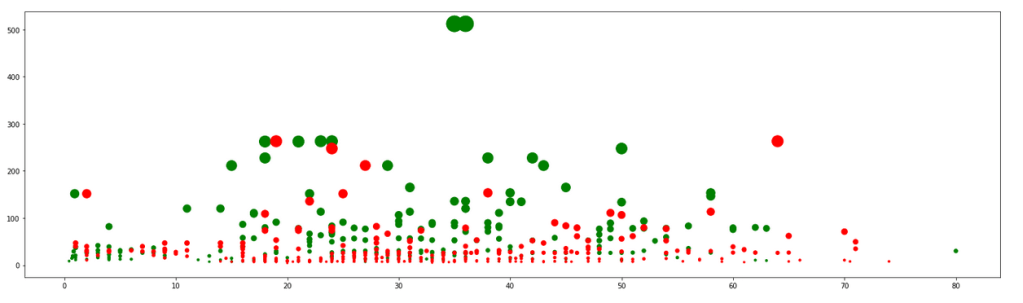
Now analyzing whether the fare of passengers’ ticket determined their survival.
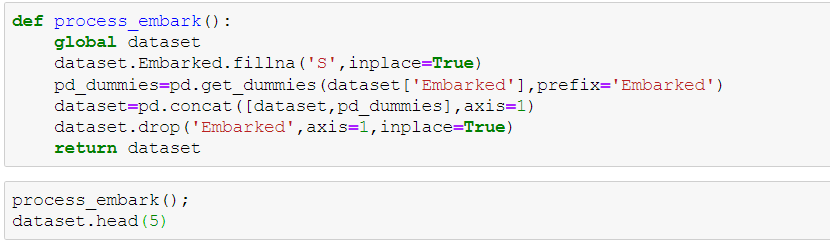
Splitting embarked class into different columns for analysis
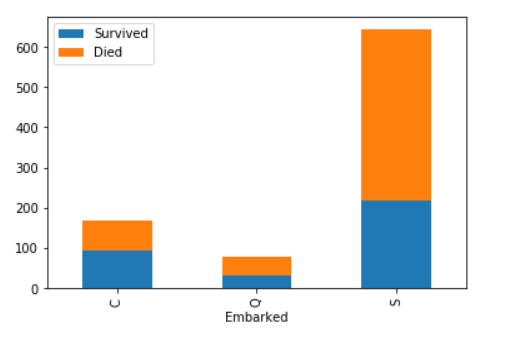
Extracting title from names to check if the model performance will get affected

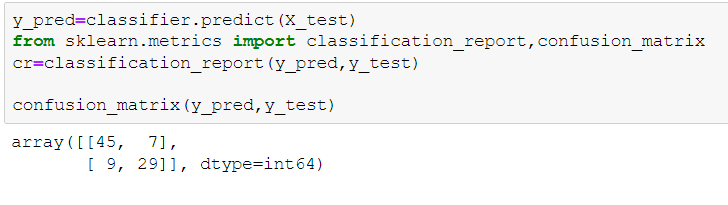
We got model accuracy of 91.7%

Running tests on test dataset.