Hello everyone, i am starting out a series of posts which will deal with the very key concepts in data science. I will be writing a series of posts as it is very difficult to accumulate all these important concepts in a single post. The posts will be divided as follows:
- Precision and Recall
- Synthetic data for imbalance datasets
- Credit card fraud detection case study.
So this blog will deal with precision and recall. I will take an example to describe this very important concept. We will be using the credit card fraud detection dataset from kaggle. You can find the dataset in my repo.
About the dataset The datasets contains transactions made by credit cards in September 2013 by European cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.Features V1, V2, … V28 are the principal components obtained with PCA, the only features which have not been transformed with PCA are 'Time' and 'Amount'.
Let us start analyzing this dataset and see what insights we can take from it.
I am assuming you are familiar with basic data processing, if not you can see my previous posts. My main aim here is to tell you about Precision and Recall.
Here are some basic steps to start with.
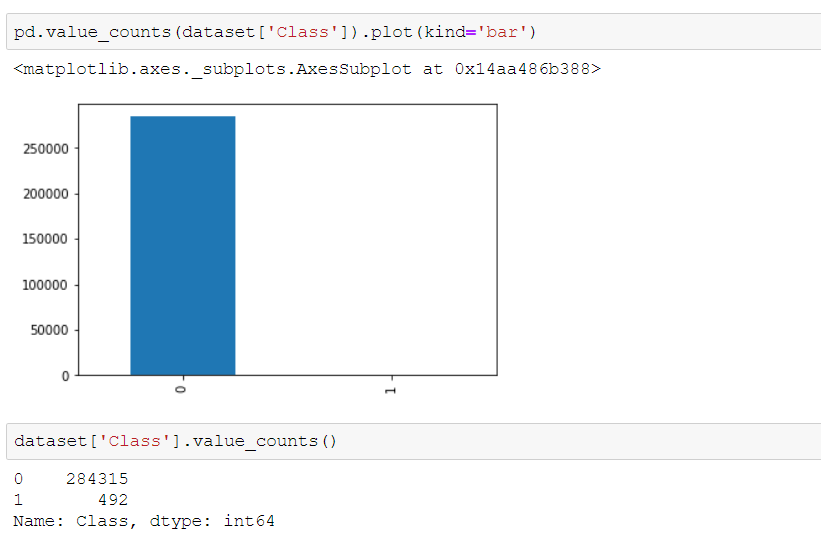
Here we see that our dataset is imbalanced, with very few fraudulent transactions. This type of dataset surely needs to be treated differently but ignoring the fact let us proceed with the mainstream process. We now split the dataset to fit it into logistic regression model.

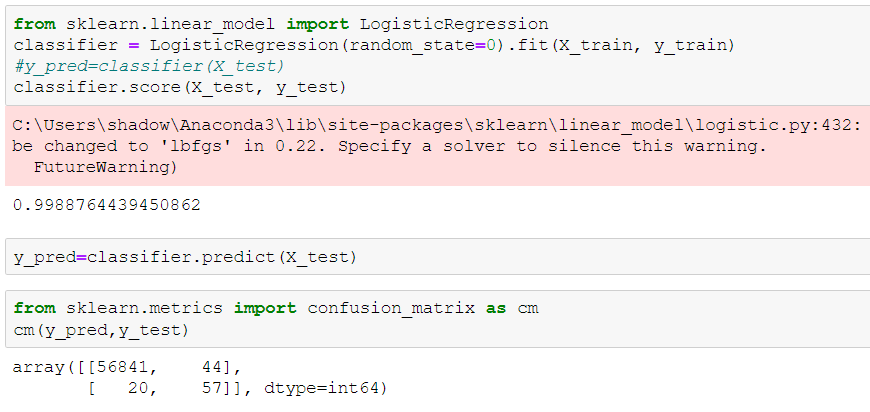
We got an accuracy of 99.8% without any trouble but do you think this is the right approach? Let us now use a dummy classifier. If you’re not aware about dummy classifier you can read about it here. It is basically used for setting a baseline for our future models.

Well now we see a definite problem here. Our model is giving 99.6% accuracy on the dummy classifier model. We sure need to go into a bit deeper to understand what is the anomaly here.
First things first, before we start any data science problem we should always see what the problem is asking us to do. If we are dealing on the larger scale say we have a problem for detecting cancer then our aim should not be to improve the overall accuracy instead we should focus on detecting patients with cancers. For the credit card fraud detection we should focus on detecting most fraudulent accounts. So in short it is always not about overall accuracy. Before moving ahead let us define some basic terminologies which we will use in future.
Confusion Matrix
This is the most basic thing you should be aware about. We will be looking at the basic binary confusion matrix here.
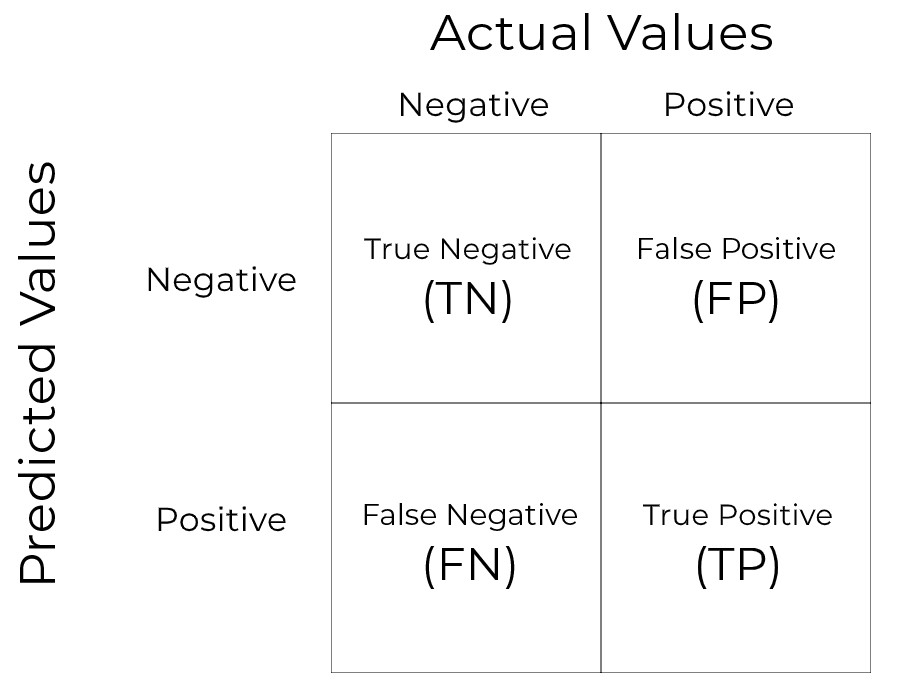
You can compare this with the confusion matrix we obtained for our model. In our problem we are aiming to detect maximum number of true positives(maximum fraudulent customers).
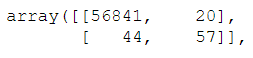
Now we will look at different methods to evaluate our model, all these methods are problem specific i.e you should choose the best one to evaluate your model according to the problem you’re dealing with.
- Accuracy- It is defined as total correct predictions divided by the total number of predictions. This evaluation matrix is used when we are not inclined towards predicting positive or negative cases.
Accuracy=(TP+TN)/(TP+TN+FP+FN)
2. Recall- It is defined as out of all the positive classes, how many of them are correctly predicted. For the credit card fraud dataset we need high recall.
Recall= TP/(TP+FN)
3. Precision- Out of all the positive predicted class, how many are actual positive.
Precision=TP/(TP+FP)
An interesting point to note here is that if we are saying our model should have high recall it doesn’t mean that we want our model to have a recall of 1.00 which is also undesirable. Recall of 1.00 will imply that FN=0. For our dataset we want to detect maximum number of fraudulent account but this doesn’t mean that we should label all the accounts as fraudulent ( this would also mean that precision will be 0 as FP is very large). Thus we have to maintain a trade-off between precision and recall. We surely want to maximize both precision and recall (here recall majorly as our dataset demands this).
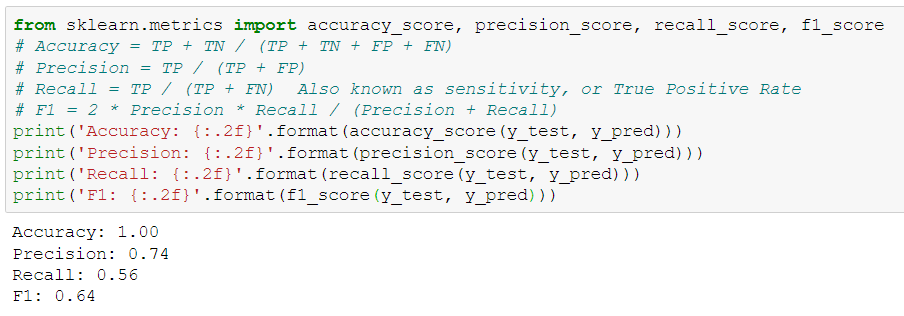
Here we see the value of precision and recall. We surely want to increase our recall. Recall of 0.56 means that our model is classifying only 56% of total fraud instances correctly leaving behind 44%.
I am ending this post here as the main idea was to give an introduction about precision and recall. In the next post we will see how to deal with imbalance dataset.
